




DAO, Repository and Service, digging deeper
November 12, 2012 by Vinicius Isola
The first time I heard the term service layer I was intrigued by it because I always used a Data Access Object to access my data. I thought it was just a new way to refer to the same thing. Of course I was wrong. A couple of years later I started to use Spring Data and again I was confronted with the Repository a different name for the same thing, at least that was what I thought, and again, I was wrong.
I’m not the kind of person that settles down until I get a complete answer for the problem, I really hate when I don’t have a precise and detailed answer. That’s why I decided to take some time and research deeper and write down my findings for all of you that are thinking the same way and get lost every time you need to name your data access layer objects.
Some may say: How can you get confused about something that is clearly different? If you think that, then this post is not for you, unless you want to help me review my content (what I would appreciate). But if you’re like me and have been writing small (10-15 model classes) web applications you’re probably standing where I am: your data layer has some characteristics of all three patterns.
Service Layer
If your application will be accessed in many different ways, for example, a web application that also has a REST or SOAP API, then a service layer can be very helpful. This layer normally contains business logic that is shared by multiple clients, like validation of constraints, authentication and authorization.
A service layer can be implemented in a separate layer that is accessed by all applications, meaning that all requests will come in through the same path, including requests from the web application. This may cause some extra overhead because every request to the web application will generate a second request to the API. The following image shows how this would work:
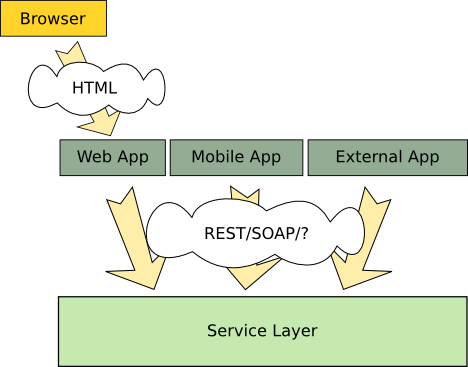
All requests come through the service layer.
Depending on how complex the service layer is this may be a good approach. Large service providers like Google, LinkedIn or Facebook have thousands of dedicated servers running their service APIs. It wouldn’t make sense to put a web application that is very thin (compared with the service layer) spread in all these servers. So it makes a lot more sense to have a few dozen of web servers running the web application that communicates with the service layer.
Another way to implement this (and how it’s done in most cases) is to have the web application implement a REST-like API that can generate different view formats including HTML, this way there would be no overhead. The next image illustrates this scenario:
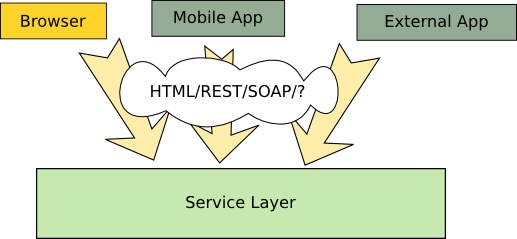
A REST-like API that renders different types of views can be used without overhead by both, the browser and other types of clients.
The service layer doesn’t need to be implemented in a different process and accessed through some protocol. What defines the service layer is that all operations are atomic, meaning that they either work or don’t. There’s no transaction that can be rolled back or committed. And as mentioned, validations and business rules are contained in it.
Repository
Here the distinction starts to get harder and polemic. Martin Fowler description of the pattern says that a Repository is a place to put complex querying and abstract the data mapping layer even further. What I understand from his description is that a repository responsability would be to isolate the application from the data layer and have a full object oriented view of the domain.
That description also states that changes happening in the objects and collections exposed by this layer should be reflected in the Data Layer. This is harder to understand if you think only about the repository. But from what I’ve learned normally a repository is used together with a unit of work.
I mentioned that this pattern is polemic because if you search the web for it you’ll find many people saying different things about it. I think that the word itself is already overloaded with different meanings which adds up for the confusion. In this StackOverflow question there’s one answer that seems to be widely accepted. Gluing that answer together with this other post I think the repository and the unit of work patterns would work the following way:
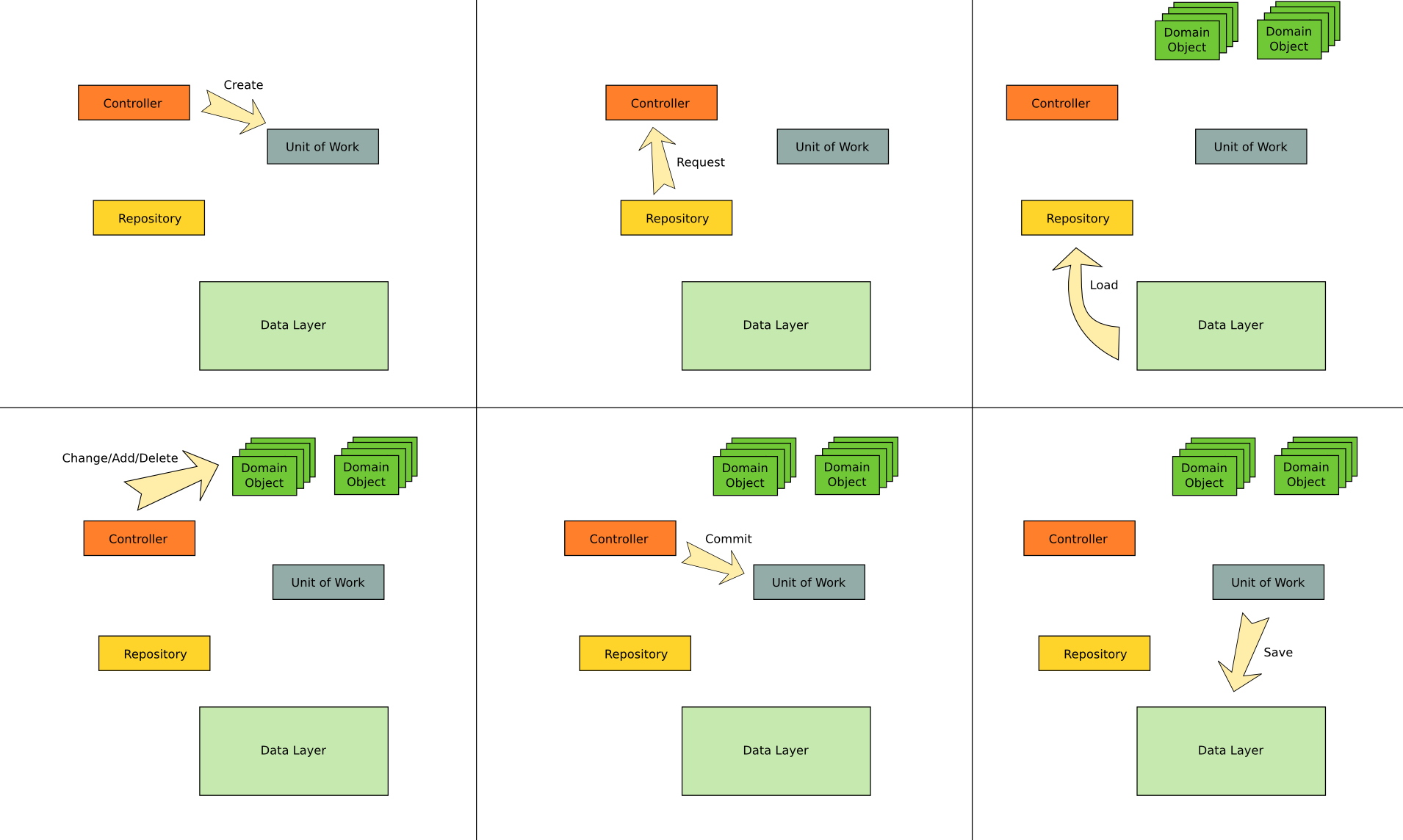
- The controller initiates an unit of work;
- The controller requests objects from the repository;
- Repository loads the data and return the objects to the controller;
- Controller modifies the objects attached to the unit of work;
- Controller asks the unit of work to commit the changes;
- Unit of work saves the object in the data layer.
Data Access Object
First of all, DAO is not a pattern, as its name describes it’s an object that abstract access to the data. The name comes from the Core JEE Patterns from Sun (now Oracle). *DAO*s isolate how the data is loaded and stored, which is important to make it easier to evolve both the application layer and the database layer independently.
Normally there is a DAO per table in the database, but with more modern technologies like ORM (Object-Relational Mapping), they started to be organized by entity (some entities may be spread in multiple tables), what makes it easier to track and maintain. Using an ORM techonlogy also makes DAO a lot smaller and easier to write. It is also possible to write generic solutions for basic operations like save/update, find one, find all and delete.
One big difference is that normally *DAO*s are normally not transactional. Which means that they normally have some way to start a transaction and finish it, either rolling back or committing it.